Data generated by organizations and user interaction can be broadly classified into 3 major categories:-
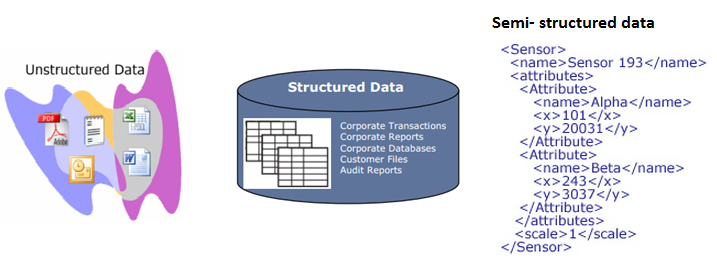
Structured data as the name suggests is information that is stored in fixed fields within a record or file. Relational databases and spreadsheets are examples of structured data. Usually displayed in named columns and rows as it is very easy to order and process such data.
Unstructured data as the name suggests is not organized and has no identifiable internal structure. Popular examples of unstructured data are emails, audio, video, social media posts, emails and many more. Usually they are in this category as the content in these files are unorganized.
Semi Structured data is one which does not conform to the formal structure of relational databases, but contains tags to define hierarchies of records and fields within data. Popular examples include JSON and XML format.
As discussed above, the fundamental difference between structured and unstructured data is that structured data is organized in a highly manageable format. Unstructured is raw and unorganized. Hence, mining through the unstructured data can be costly and problematic. On the other hand, mining through structured data is relatively simplistic and straightforward. Unstructured data is growing at a very fast pace because rich data types like pictures, music, movies provides superior user experience as compared to just text. Structured Query Language (SQL) is the programming language created for managing and querying structured data whereas Hadoop is used for data analysis of unstructured data.
In today’s business world, structured data is generated through transactions and unstructured data represents communications between people and documents. Generally email is considered as structured data since it is indexed on date, sender, recipient and subject. But, it is still unstructured data as the body of the email remains unstructured. Hence, classified as semi- structured.
Volume of Structures, unstructured and semi structured data
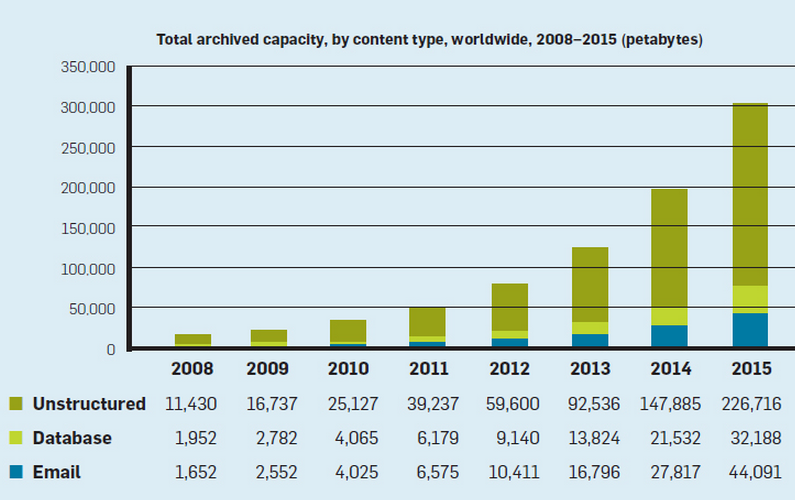
As depicted by the graph, the volume of unstructured data is continuously increasing at a very fast pace and has quadrupled from 2008 to 2015. The major contributing factors for this rapid increase is the increase in usage of social media and mobile devices. Semi- structured and structured data has also increased in volume but not as much as unstructured data.
Data warehouse – It is a single logical large repository of data generated from within the company. It integrates data from different sources to create a single knowledge base. Data warehouses are designed to facilitate reporting, decision support and analysis to guide the management’s decisions about the company. Historical data is kept within the data warehouse and this data is non-volatile. Generally a data warehouse is built from the transactional data and is used specifically for query and analysis. It is time variant as data warehouse is only accurate and valid for a specific period in time or interval.
Limitations of Data warehousing
Complexity in integration of data from disparate sources is a challenge -there are several cases when there are disagreements within the organization about data that has to be integrated. For example different departments may have different views of data and there can be a never ending debate on who has the correct view of data.
Unstructured data can’t be stored in its raw form in typical data warehouses- The nature of unstructured data makes it hard to search, retrieve and analyze this data and directly integrating this unstructured data with structured data is a challenge. Advanced techniques like natural language processing, text tagging is required to convert unstructured to structured data.
Required data not captured in transactional systems i.e. Lack of data and poor quality - data is loaded into the data warehouse from the transactional systems, therefore some attributes might not be captured in transactional systems which might be very useful for data warehouses
Inflexible to changing business requirements/questions/data types- a lot of time is spent on ETL process and once data is loaded in the data warehouse, it is difficult and costly to answers the questions that may arise over time and correct errors in the ETL process. Also, data type changes in source systems like ranges, schema are difficult to accommodate in later stages.
High demand for resources – the data warehouse is a huge repository and hence requires large storage capacity. The amount of data that can be stored is restricted by the storage capacity of data warehouse.
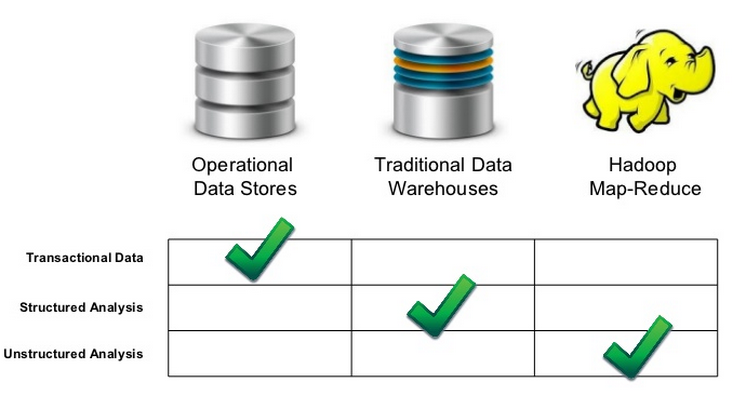
Future of Data warehousing with the advent of Big Data
Data warehouses were originally built to organize data to discover and analyze historical trends. They were built to handle structured data from ERP systems and not the unstructured data generated from social media like Facebook, Twitter, Mobile devices, web traffic etc. But, now due to data explosion i.e. more data is being generated in more places by more number of people and applications at a very fast pace. With the advent of Big data, mobility, cloud, NoSQL, the data warehouses face additional challenges. The below mentioned points pose a challenge to the traditional data warehouses:-
- Explosion in real time analysis
- Accessibility of Big Data streams
- Multi format multi type of data
- Scaling across different geographies
This does not mean that Big data will replace data warehouses. They complement each other and their usage will be dependent on the business requirement. The open source Hadoop that is capable of processing unstructured data will optimize the data warehouse environments and reform the generation of data warehouses. The traditional data warehouses will evolve into analytical warehouses capable of processing structured and unstructured data. Newer data warehouses will be bigger, better and faster than ever before which will transform data into useful information. Real time analytics will be possible as information will be loaded into the data warehouse instantly and go beyond just dashboard and reports to analyze day to day operations. Multi structure formats like XML, JSON will be supported and processing of the data will be offered on the cloud.
The concept of upgrading the old data warehouse will fade away. It will be a living system that will grow seamlessly as per the need of the organizations.

The result of these advancements in technology will be reduced costs of ownership for the data warehouse and increase rate of investment for the company. The data warehouse will be completely transformed and become a dynamic data integration and transformation engine that delivers consistent performance on the cloud.
References
- http://www.whamtech.com/adv_disadv_dw.htm